elk简述
传统日志管理问题
在项目初期的时候,大家都是赶着上线,一般来说对日志没有过多的考虑,当然日志量也不大,所以用log4j就够了,随着应用的越来越多,日志散落在各个服务器的logs文件夹下,确实有点不大方便
当我们需要日志分析的时候你大概会这么做:直接在日志文件中 grep、awk 就可以获得自己想要的信息
但是这样的方式有很多问题:
日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询
应用太多,面临数十上百台应用时你该怎么办
随意登录服务器查询log对系统的稳定性及安全性肯定有影响
如果使用人员对Linux不太熟练那面对庞大的日志无从下手
elk简介
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件
ElasticSearch
这是一个基于Lucene的分布式全文搜索框架,可以对logs进行分布式存储,有点像hdfs。此为ELK的核心组件,日志的分析以及存储全部由es完成LogStash
它可以流放到各自的服务器上收集Log日志,通过内置的ElasticSearch插件解析后输出到ES中Kibana
它可以多维度的展示es中的数据。这也解决了用mysql存储带来了难以可视化的问题。他提供了丰富的UI组件,简化了使用难度
elk作用
日志统一收集,管理,访问。查找问题方便安全
使用简单,可以大大提高定位问题的效率
可以对收集起来的log进行分析
能够提供错误报告,监控机制
elk架构选择
一般使用普通架构即可
普通架构
ElasticSearch:核心 提供查询,全文检索
Kibana:页面展示,及方便查询
Logstash:收集日志 主要有过滤功能,格式化,和其他个性化需求
使用场景:
能解决50G以下的log,这个50g指的是es里面的总量–此时一般es所在的机器配置是8G,es比较吃cpu内存
高级架构
ElasticSearch:核心 提供查询,全文检索
Kibana:页面展示,及方便查询
FileBeat :轻量级收集日志系统,速度快,稳定不占资源
Redis:缓冲,防止把es搞垮了,和kafka二者取其一
Kafka:消息中间件,可缓存大数据量,日志一般存半个月
使用场景:
适用于一天产生几十g日志
推荐算法模型–》元数据来源于log,redis和kafka还有优势是做推荐的时候,可以即分发给es也分发给推荐算法
elk部署
下载地址:
本次安装的版本信息:
JDK1.8
elasticsearch-5.6.4
logstash-5.6.3
kibana-5.2.0
elasticSearch部署
下载的包传到服务器上解压后
修改es的配置
|
|
要修改的内容如下
修改linux配置
elasticSearch不允许root用户启动,新建用户用于启动elasticSearch
es5.0后修改limit限制,不修改启动会报错
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决max number of threads [1024] for user [apps] is too low, increase to at least [2048] 报错
解决max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]报错
启动测试
启动
开放端口
浏览器访问测试:
http://es所在机器ip:9200/
出现一串包含版本信息的json即为安装成功
logstash部署
解压,在config目录建:logstash.conf,输入以下内容
配置包含input ,filter,output三大块
其中input是吸取logs文件下的所有log后缀的日志文件
filter是一个过滤函数,配置则可进行个性化过滤
output配置了导入到hosts为127.0.0.1:9200的elasticsearch中,每天一个索引
start_position:
是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,则不会从最开始读取。重启读取信息不会丢失
bin目录下启动logstash了,配置文件设置为config/logstash.conf
启动命令:
配置不同的logpath
在config目录下建立多个.conf文件,每个文件指定不同path
指定启动目录:
kibana部署
这个安装比较简单,解压后在kibana.yml文件中指定一下你需要读取的elasticSearch地址和可供外网访问的bind地址就可以了
修改内容如下:
启动
开放端口
浏览器访问测试:
http://kibana所在机器ip:5601/
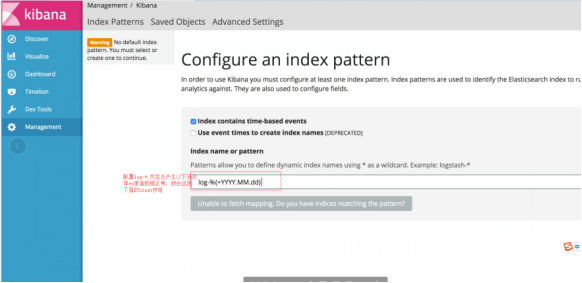
创建索引:
进入之后,在左侧栏菜单最后一项,创建索引,进入时没有创建按钮
我们在本机的/logs文件夹下创建一个简单的1.log文件,内容为“hello world”,然后在kibana上将logstash- 改成 log ,Create按钮就会自动出来
插件安装
elastic-head插件
下载
https://github.com/mobz/elasticsearch-head/archive/master.zip
解压
执行命令
如果没安装nodejs的话需要安装
如果node.js版本过低,则需要升级
升级node.js
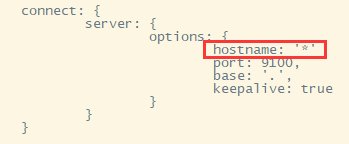
修改配置
在connect节点下 增加hostname属性,设置为* 注意加,号
修改head链接
将
把localhost修改成自己es的服务器地址
如果之前没在es的配置文件中配置以下内容的话,配置下(我上面es已经配置)
运行
开放端口
浏览器访问测试:
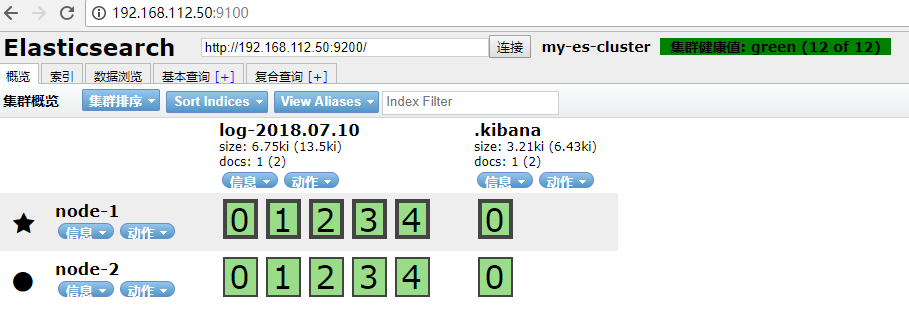
http://插件所在服务器ip:9100
elasticSearch集群部署
以上配置完成后,elk已经可以正常使用,这里在记录下es集群的部署,这里在一台机器上部署集群,上面已经部署好的es为主节点,其 elasticsearch.yml 的配置内容如下:
复制一份主节点的es或重新解压一份es,修改其 elasticsearch.yml 的配置内容如下:
如果一台机器内存不够,可以修改es的内存配置,例如这里可以将master内存改小一点
将2G改为1G
为了方便查看我将上面es的文件夹做了重命名,因此给elasticsearch重新授权
添加公作节点使用的外部端口
启动工作节点,在启动master节点
成功启动后控制台打印
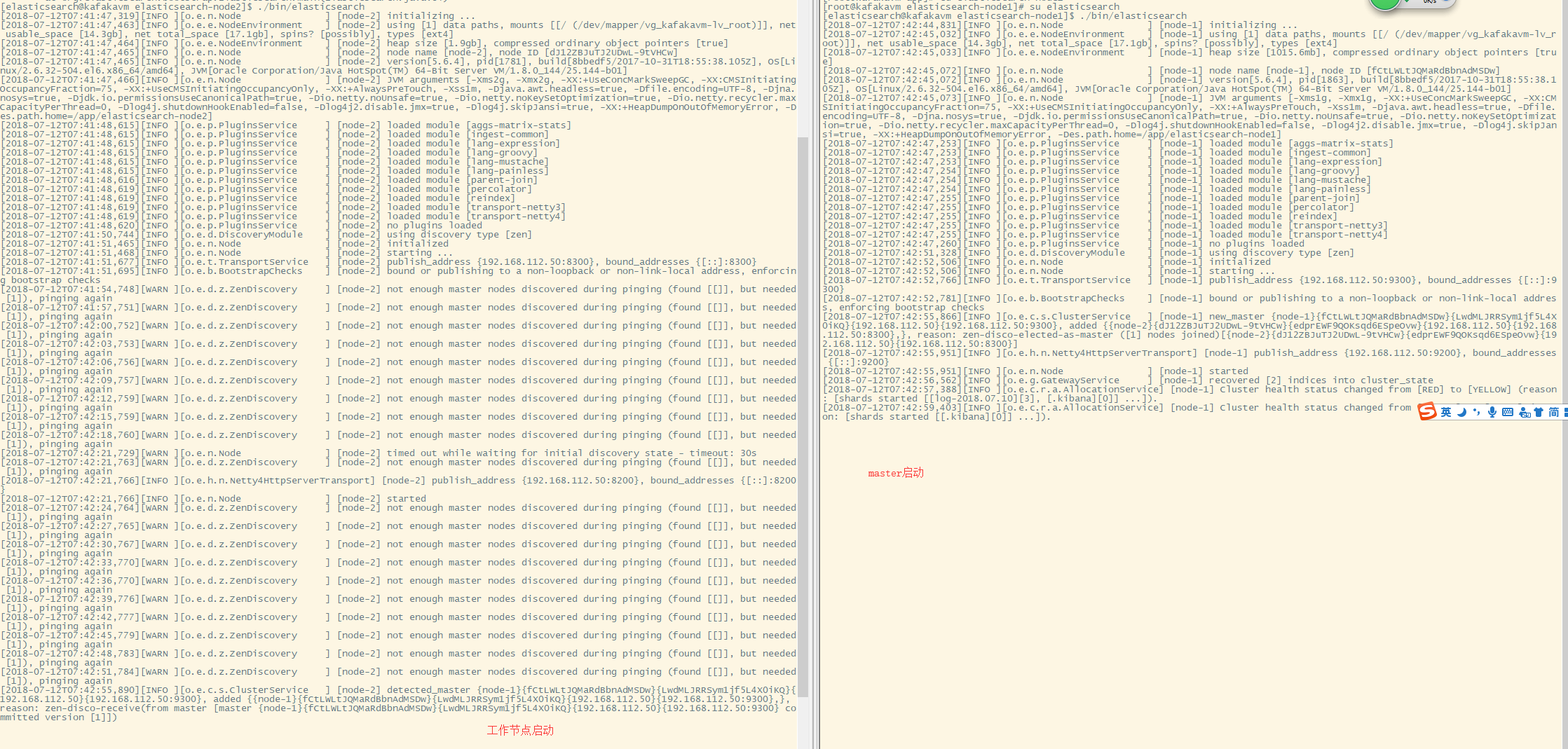
启动head插件,在浏览器访问